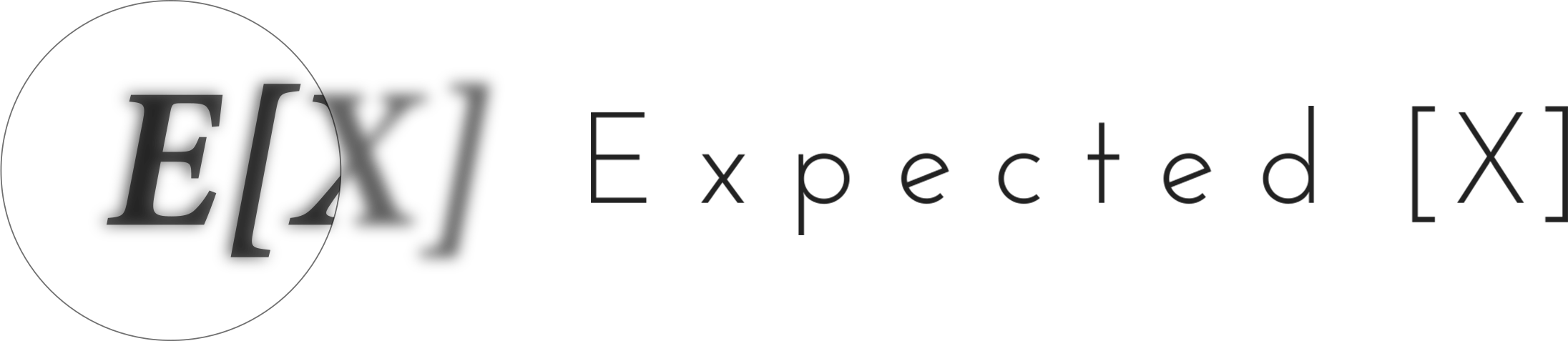
Who wants to hear a story about data?!
…(silence)…
Understandably, not a lot of people would raise their hands to an intro like that. For me, however, data has sculpted my career path and led to many exciting opportunities over the life of my profession. It hasn’t been easy — I think any entrepreneur would tell you the same and surely the content and media attention around self-starting individuals would concur. But I’m not here to tell you about the hardships of starting a business. Rather, I’m here to tell you about how I have grown (and continue to grow) into a role within an industry I never really set out to enter. We are very lucky to live in the Information Age where autodidacts like me will never run out of resources to learn what they need to achieve success in their given field. If you are interested in entering the machine learning/data science field, I hope this provides you the encouragement to set off or carry on!
A Career in Consumer Market Research
How did I get into this industry? No really — I’m still not entirely sure how I ended up in my first position as a market research project manager. When you are about to graduate college, I think you tend to have a “spray-and-pray” mentality to getting your first job. Fire off those resumes online or drop them off the top of a tall building like a ticker-tape parade and see what sticks.
While I did entertain interviews from more than one business, I ultimately accepted an entry-level position in Indianapolis, Indiana that I still can’t recall ever reaching out to initially (must have been one of those ticker-tape resumes). So began my first foray into using data to drive business decisions.
When someone asks me what “consumer market research” is I typically tell them it’s surveys and focus groups.
“Oh, yeah! I know what you mean now. Yeah, I NEVER do those.”
It’s funny how many people over the years have responded the same way to that! It makes me wonder exactly who responds to online surveys and participates on focus groups these days. The whole purpose of consumer market research is to understand the mind of the consumer: what makes them buy? What makes them chose one product over another? What will they buy in the future? We answer these questions by analyzing data.

Initially, I enjoyed this industry because I found it fascinating to peer inside the mind of the consumer. While this was private industry, there were still inklings of academia when it came to study design and statistical analysis. Furthermore, research (whether academic or business-related) is an art and a science — something that didn’t fall short on someone like me who grew up playing with Legos and reading non-fiction history or science books for my elementary school’s summer reading programs (which my mother had to argue I’d actually read in order to win my pizza party)!
I continued to work in consumer market research for some time moving eventually to Chicago where I was employed initially at a boutique agency and eventually the largest market research company in the world.
But I was falling out of love with the industry. Why you might ask? Well:
- There was a general reluctance to move away from the “bread-and-butter” survey and focus group approaches even though year-over-year response rates had dropped significantly and an assortment of new approaches became available like social media mining.
- The data quality was atrocious and no one seemed to care. Blatant misrepresentation, surveys with logical fallacies that allowed nonsensical answers, unrepresentative samples, and the general growth of “profession survey takers” (if not automated, survey-taking “bots”) fudging the data every time our security measures failed to work.
- Executives and account managers providing clients with “insights” and “recommendations” based on a solid misunderstanding of basic statistical tenants (i.e. focusing solely on arbitrary p-value interpretation for instance). Unsuspecting clients believing what they are told and seldom questioning the methodology. Essentially, the blind leading the blind.
It was around this time that terms like “Big Data” began to enter the conversational lexicon of business executives and journalists alike. I was intrigued and in my typical fashion, I wanted to learn more. What I found seemed to be an alternative means of understanding the consumer mind. Data was being collected literally everywhere around us. Smartphones and the Internet made that a reality. Additionally, people are much more likely to provide better data on their behaviors when they aren’t directly questioned or even realize they are providing data in the first place. I think the adage “Actions Speak Louder Than Words” is appropriate here. Since nearly every action we take today, like our FitBit biometrics, what we purchase online or in stores, how we drive our cars, and possibly every button we click on our smartphone apps and websites is registered as a data point somewhere there must be a way to use that data more effectively than unsubstantial survey data.
I approached many executives and sales team leaders at my organization at the time with an array of ideas about how we could utilize these new data sources to transition away from the survey/focus group methodology. I’ve heard that if you complain about how something is done in a business to “top brass” (or in my case maybe the “middle copper” if there is such a thing) you better have ideas how to improve the situation.
Instead, I was released.
Preparing For Career 2.0 in Data Science
I knew that my interest in data and the potential power it had to answer business questions, generally improve efficiencies via automation, and even provide competitive advantages wasn’t unwarranted (although I remember a supervisor of mine once saying many years ago that “Big Data” was just a fad and it wouldn’t amount to anything in the long run — that was probably 8 years ago now). Long before my premature departure from my organization, I had begun to ramp up my self-study on the topic. As I stated earlier, the Internet provided a litany of resources which, while large back then, isn’t even comparable to the resources today just a few years later.
I fully inundated myself in the topic. Keep in mind that although I received my MS, I did not pursue a Ph.D. While many might write off a machine learning practitioner without a Ph.D., I beg to differ. While everyone learns differently, I found these resources extremely helpful in the early going in lieu of pursuing an expensive and time-consuming higher degree:
- Online courses offered (sometimes for free) from academic institutions and private organizations alike. My favorites are from Stanford University, Johns Hopkins, and private organizations like Coursera, Udemy, edX. Back then, there were only a smattering of courses in this field. Now, there are several hundred if I wagered a guess and full-fledged online degree programs from prestigious universities like MIT, Columbia, and Northwestern to name only a few.
- Machine learning competitions provide another means of active/applied learning at no cost other than your time. Participants are given a problem (often presented by both public and private institutions) and data to build an algorithm for solving it. Typically, in this sense “solving” a problem is equitable to building a machine learning model for predicting some future event or outcome with the highest degree of accuracy using historical data related to that event/outcome. While Kaggle is the premier website for these competitions, others include CrowdANALYTIX, DataKind, and DrivenData.
- Learning on-the-job is essentially the best approach to learning machine learning or anything for that matter. Real-world data problems are notoriously messy endeavors and even after building a viable model you still have to go through the rigamarole of putting your solution into production at scale (enter, cloud platforms like AWS which involve learning an entirely new set of IT skills). Thankfully, again, the wealth of Internet-based knowledge comes to the rescue.
There was nothing easy or quick about the process I went through and not everyone thrives in an environment where the only one accountable for their progress is themselves. It took me over five years to feel comfortable with the foundational aspects of machine learning. Finally, after several small projects (including one I was lucky to snag with the U.S. Department of Energy) and more on the horizon, I incorporated as Expected X.
Machine Learning and Expected Value
I’m actually surprised that I don’t get asked what “Expected X” means more often. Some people I speak with say “oh, yeah that’s clever” to which I can only assume that they are knowledgeable in statistics. I, myself, have never developed proper verbiage so why not now? I suspect it will be a great lead-in to the rest of this article’s content.

Expected X really refers to “expected value” which is a term in statistics represented formally by the notation “E[X].” Expected value is just the value we’d expect a variable to take, on average, after several repetitions or iterations of some, say, experiment. In simple terms, you could equate this to saying “what’s the expected value of getting tails when I flip a coin?” To which the answer would be “0.5” or “50%” — we have two possible outcomes from a coin flip (heads/tails) each with an assumed probability of 0.5.
Expected X is more than just a business name, it’s a personal philosophy of mine stemming back from my market research days. Turn on the news and you are often presented with a story regarding some new research study out of the University of So-and-So proclaiming something like “a chemical in coffee is linked to cancer” only to be followed a few weeks later by a new study proclaiming “coffee’s health benefits!” The point is that a single, one-off research study hardly lays the ground for truth and causality. In fact, most scientists worth their weight would agree that we can only move the needle closer and closer to accepting a given hypothesis and can never actually know what “truth” is. Deep, isn’t it?
That’s my business philosophy as well — machine learning solutions are never a magic bullet. It takes iterations many, many times over to improve an algorithm’s accuracy, precision, or whatever metric you are using to measure its efficacy. Conveying this philosophy is difficult considering the slew of content available proclaiming machine learning or deep learning or artificial intelligence (all three terms with different meanings frequently used interchangeably by the mass media) as a be-all, end-all future business model. Sound familiar, blockchain?
A Final Note: Overcoming Imposter Syndrome
It’s easy to contract “imposter syndrome” in the machine learning business and I am not immune. Imposter Syndrome, for those that don’t know, is the doubting of one’s abilities and accomplishments compared to other individuals in their given field. Having been taught via “trial-by-fire” within a corporate setting as well as my own self-study, I have frequently questioned if I know enough to master this discipline’s exceedingly-technical ecosystem.
So on a final note, I have a few words from my experience that help me push through and elevate my passions:
- You DON’T need a Ph.D. to be effective in machine learning. Although most, if not all, job postings seem to require a Ph.D. in math, statistics, computer science, etc., I’ve found those requirements to be often be written by individuals with very little understanding of what they are looking for. In fact, some of the same job postings will require applicants to have X years of experience in some technology that hasn’t even existed that long! To me, passion and the drive to continue to learn are far more important — not just in machine learning but any line-of-work you find yourself in.
- You DON’T always need to use the newest, shiniest approaches when applying machine learning to business problems. Again, the media loves to hype the latest and greatest. This is apparent to me, personally, since most of my Machine Learning and Deep Learning Fundamentals with Python classes are met with participants asking 5 minutes into class “When are we going to start talking about neural networks?” The fact is that most often these types of approaches are overkill. You can solve a plethora of business problems using simple regression techniques. Unfortunately, regression isn’t the basis for a very sexy machine learning article.
- You DON’T have to be an expert in all aspects or tangential fields of machine learning. While there is always something new to learn in this field (or any), I’ve found it easier to simply be conversant in some areas than a full-fledged pro. For instance, AWS is probably the most commonly used cloud platform for deploying machine learning solutions at scale but in itself, it is an entirely different field from machine learning — something more attuned to the IT world than the ML world. While I am AWS certified, I would never go it alone deploying a model in AWS. Find complementary talent rather than risk your neck trying to be the omnipotent professional.
All that being said, I hope the reader has gained something from my personal perspective. While your own professional interests might lie elsewhere, I believe much of the preceding could still be applicable to your own situation. Now, I suppose I could ask you if you Agree or Disagree with me (maybe on a scale from one to five, for instance), but that might not be a very trustworthy methodology!


Recent Comments